BERT 全名为 Bidrectional Encoder Representations from Transformers, 是 Google 以无监督的方式利用大量无标注文本生成的语言代表模型,其架构为 Transforer 中的 Encoder.
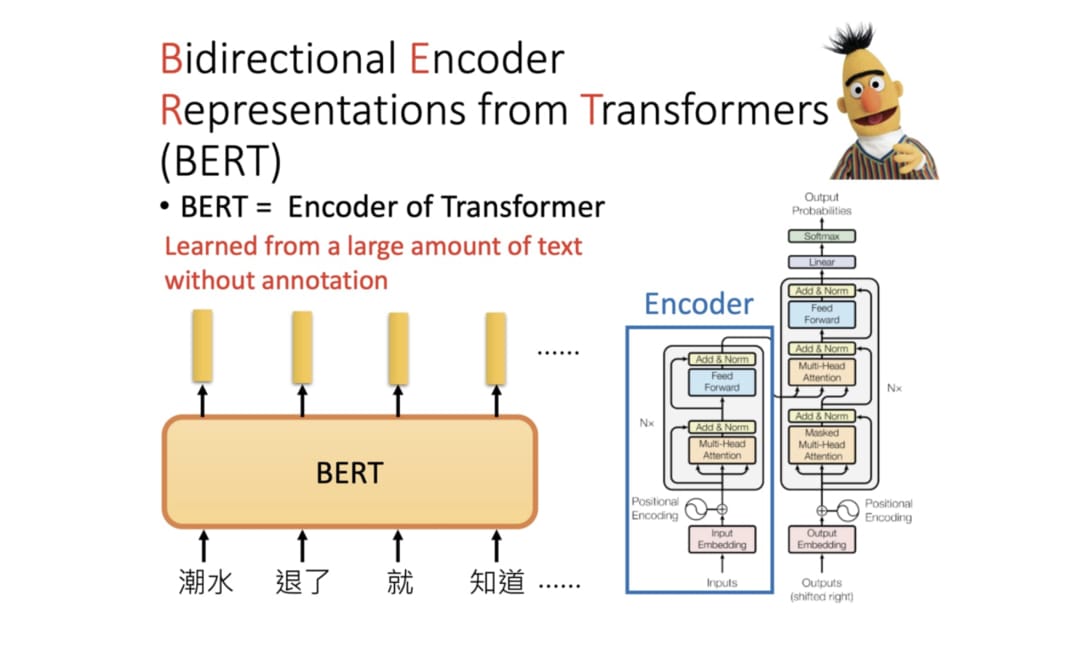
BERT 是 Transformer 中的 Encoder, 只是有很多层 (
图片来源]
以前在处理不同的 NLP 任务通常需要不同的 Language Model (LM),而设计这些模型并测试其性能需要不少的人力,时间以及计算资源。 BERT 模型就在这种背景下应运而生,我们可以将该模型套用到多个 NLP 任务,再以此为基础 fine tune 多个下游任务。fine tune BERT 来解决下游任务有5个简单的步骤:
- 准备原始文本数据
- 将原始文本转化成 BERT 相容的输入格式
- 利用 BERT 基于微调的方式建立下游任务模型
- 训练下游任务模型
- 对新样本做推论
那 BERT 模型该怎么用呢,thanks to 开源精神,BERT 的作者们已经开源训练好的模型,我们只需要使用 TensorFlow or PyTorch 将模型导入即可。
1
2
3
4
5
6
7
8
9
10
|
import torch
from transformers import BertTokenizer
from IPython.display import clear_output
PRETRAINED_MODEL_NAME = "bert-base-chinese" # 指定简繁中文 BERT-BASE 预训练模型
# 取得此预训练模型所使用的 tokenizer
tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)
clear_output()
|
上述代码选用了有 12 层 layers 的 BERT-base, 当然你还可以在 Hugging Face 的 repository 找到更多关于 BERT 的预训练模型:
- bert-base-chinese
- bert-base-uncased
- bert-base-cased
- bert-base-german-cased
- bert-base-multilingual-uncased
- bert-base-multilingual-cased
- bert-large-cased
- bert-large-uncased
- bert-large-uncased-whole-word-masking
- bert-large-cased-whole-word-masking
这些模型的区别主要在于:
- 预训练步骤使用的文本语言
- 有无分大小写
- 模型层数
- 预训练时遮住 wordpieces 或是整个 word
接下来我就简单的介绍一个情感分类任务来帮大家联系 BERT 的 fine tune
首先加载我们需要用到的库:
1
2
3
4
5
6
7
8
9
10
11
|
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import torch
import transformers as tfs
import warnings
warnings.filterwarnings('ignore')
|
然后加载数据集,本文采用的数据集是斯坦福大学发布的一个情感分析数据集SST,其组成成分来自于电影的评论。
1
2
3
4
5
|
train_df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)
train_set = train_df[:3000] #取其中的3000条数据作为我们的数据集
print("Train set shape:", train_set.shape)
train_set[1].value_counts() #查看数据集中标签的分布
|
得到输出如下:
1
2
3
4
|
Train set shape: (3000, 2)
1 1565
0 1435
Name: 1, dtype: int64
|
可以看到积极与消极的标签对半分。
这是数据集的部分内容:
1
2
3
4
5
6
7
8
9
10
11
12
|
0 1
0 a stirring , funny and finally transporting re... 1
1 apparently reassembled from the cutting room f... 0
2 they presume their audience wo n't sit still f... 0
3 this is a visually stunning rumination on love... 1
4 jonathan parker 's bartleby should have been t... 1
... ... ...
6915 painful , horrifying and oppressively tragic ,... 1
6916 take care is nicely performed by a quintet of ... 0
6917 the script covers huge , heavy topics in a bla... 0
6918 a seriously bad film with seriously warped log... 0
6919 a deliciously nonsensical comedy about a city ... 1
|
我们对原来的数据集进行一些改造,分成 batch_size 为 64 大小的数据集,以便模型进行批量梯度下降
1
2
3
4
5
6
7
8
9
10
|
sentences = train_set[0].values
targets = train_set[1].values
train_inputs, test_inputs, train_targets, test_targets = train_test_split(sentences, targets)
batch_size = 64
batch_count = int(len(train_inputs) / batch_size)
batch_train_inputs, batch_train_targets = [], []
for i in range(batch_count):
batch_train_inputs.append(train_inputs[i*batch_size : (i+1)*batch_size])
batch_train_targets.append(train_targets[i*batch_size : (i+1)*batch_size])
|
在这里我们采取 fine-tuned 使得 Bert 与线性层一起参与训练,反向传播会更新二者的参数,使得 Bert 模型更适合这个分类任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class BertClassificationModel(nn.Module):
def __init__(self):
super(BertClassificationModel, self).__init__()
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased')
self.tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
self.bert = model_class.from_pretrained(pretrained_weights)
self.dense = nn.Linear(768, 2) #bert默认的隐藏单元数是768, 输出单元是2,表示二分类
def forward(self, batch_sentences):
batch_tokenized = self.tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,
max_len=66, pad_to_max_length=True) #tokenize、add special token、pad
input_ids = torch.tensor(batch_tokenized['input_ids'])
attention_mask = torch.tensor(batch_tokenized['attention_mask'])
bert_output = self.bert(input_ids, attention_mask=attention_mask)
bert_cls_hidden_state = bert_output[0][:,0,:] #提取[CLS]对应的隐藏状态
linear_output = self.dense(bert_cls_hidden_state)
return linear_output
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#train the model
epochs = 3
lr = 0.01
print_every_batch = 5
bert_classifier_model = BertClassificationModel()
optimizer = optim.SGD(bert_classifier_model.parameters(), lr=lr, momentum=0.9)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
print_avg_loss = 0
for i in range(batch_count):
inputs = batch_train_inputs[i]
labels = torch.tensor(batch_train_targets[i])
optimizer.zero_grad()
outputs = bert_classifier_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print_avg_loss += loss.item()
if i % print_every_batch == (print_every_batch-1):
print("Batch: %d, Loss: %.4f" % ((i+1), print_avg_loss/print_every_batch))
print_avg_loss = 0
|
1
2
3
4
5
6
7
8
9
10
11
|
# eval the trained model
total = len(test_inputs)
hit = 0
with torch.no_grad():
for i in range(total):
outputs = bert_classifier_model([test_inputs[i]])
_, predicted = torch.max(outputs, 1)
if predicted == test_targets[i]:
hit += 1
print("Accuracy: %.2f%%" % (hit / total * 100))
|
预测结果如下:
由此可见,经过微调后的模型效果还不错。
好了,这篇 blog 就讲到这里吧。
我是 Anthony, 我们下次再见.
参考文章:
- 进击的 BERT: NLP 界的巨人之力与迁移学习
- 基于 BERT 模型的文本情感分类实例解析
- 李宏毅教授介绍 ELMO, BERT, GPT 的视频